Дата публикации: 06.05.2022
Қыдыр Айдос Серікұлы
Алматы технологиялық университеті
Научный руководитель: Иманбаева Кайрат Сабетович
Алматы технологиялық университеті
Машинное обучение (МО) и глубокое обучение (ГО) используются для обнаружения опухолей головного мозга, рака шейки матки, рака молочной железы, обнаружения COVID, распознавания физической активности, обнаружения тепловых ощущений и оценки когнитивного здоровья людей с деменцией. Достижения в области здравоохранения делают его более эффективным, чем традиционные методы диагностики. Согласно медицинским отчетам, публикуемым Глобальной статистикой рака , каждый год прибавляется 493 000 пациентов со злокачественными новообразованиями шейки матки, среди которых 15% составляют пациентки со злокачественными новообразованиями. Это заболевание в основном встречается в развивающихся странах с коэффициентом смертности 83%. Заметно в африканских странах , например, в Уганде, которая занимает четырнадцатое место среди самых высоких показателей заболеваемости злокачественными новообразованиями шейки матки с 65% подтвержденных случаев. Заражение вирусом папилломы человека в основном связано со злокачественными новообразованиями шейки матки. Заражение передается половым путем. Сексуальное поведение, связанное с возрастом первого полового контакта и сексуальной активностью сообщника, связано с повышенным риском заражения вирусом папилломы. В этом случае злокачественное новообразование шейки матки можно значительно предотвратить с помощью доступного скрининга и обнаружения, чем другие виды злокачественных новообразований, и это имеет решающее значение для реализации ожидаемого риска. Злокачественное образование шейки матки является злокачественной опухолью. Клетки ткани шейки матки размножаются и размножаются аномально без регулируемого деления клеток и причины гибели. Если опухоль становится злокачественной, клетка перемещается в другие области тела, так что определенные участки впоследствии инфицируются, и в наиболее серьезных ситуациях этого можно избежать за счет ранней идентификации . Смертность от злокачественных новообразований шейки матки можно снизить, если применять эффективные стратегии скрининга . С быстрым развитием современных клинических инноваций и инноваций в компьютерных технологиях различные стратегии скрининга и диагностики зависят от компьютерных (CAD) архитектур. Процедура извлечения применимой информации из источников информации известна как интеллектуальный анализ данных. Реальная информация состоит из грязной информации, например, неточной и неполной. В соответствии с этим очистка и изменение сырой информации для обеспечения надежной аналитической доставки может точно отразить результат. Он реализован на наборе данных. Набор данных о раке шейки матки, полученный для исследования, содержит избыточность, пропущенные значения и шум. Методы добычи полезных ископаемых считаются одной из самых больших проблем и важных областей изучения в медицине из-за растущей важности проблем со здоровьем. Система интеллектуального анализа данных может улучшить процесс скрининга рака шейки матки с помощью извлеченных знаний. В медицинском секторе эти методы помогают не только находить сходства и корреляции между такими симптомами, но и прогнозировать заболевания. Применяя несколько методов интеллектуального анализа данных, можно немедленно рекомендовать непрерывные исследования и лечение, что приводит к спасению жизни, особенно при раке шейки матки. Первым шагом является предварительная обработка 80 % информации, которая играет жизненно важную роль в ходе всех операций по интеллектуальному анализу данных.
Случайный лес (RF) используется для определения основных функций в нашем исследовании, которые улучшают качество набора обучающих данных. RF строит лес классификаций деревьев, в котором каждое дерево растет на данных выборки начальной загрузки, а характеристики каждого другого узла дерева выбираются из случайного подмножества всех характеристик. Окончательный уровень сущности измеряется путем голосования по всем деревьям в лесу. Несколько существенных преимуществ метода RF делают его идеальной методологией для изучения конкретных биологических данных в результатах исследований фармакогеномики. Кроме того, он может вместить широкий спектр как качественных, так и количественных входных векторов. Во-вторых, он проверяет важность атрибута при оценке типа, тем самым предоставляя ориентир для выбора признаков. В-третьих, RF генерирует точный классификатор для беспристрастного внутреннего обобщенного анализа в процессе роста леса. Наконец, РФ относительно стабильна перед лицом этиологической изменчивости и достаточно небольшого количества пропущенных данных .
В этой статье сделан следующий вклад:
• CervDetect применяет алгоритмы машинного обучения к медицинским данным для более глубокого понимания и оценки элементов риска злокачественного образования шейки матки.
• Использует корреляцию Пирсона между входными и выходными переменными для предварительной обработки данных.
• CervDetect использует технику выбора радиочастотных признаков для выбора важных признаков.
• Предлагает гибридный подход, сочетающий РЧ и неглубокую нейронную сеть для обнаружения рака шейки матки.
• Эффективно повысить уровень обнаружения по сравнению с современными исследованиями.Остальная часть устроена следующим образом. Раздел 2 представляет обзор литературы. Раздел 3 представляет набор данных и предварительные сведения. Раздел 4 представляет предлагаемый метод.
Предлагаемые методы
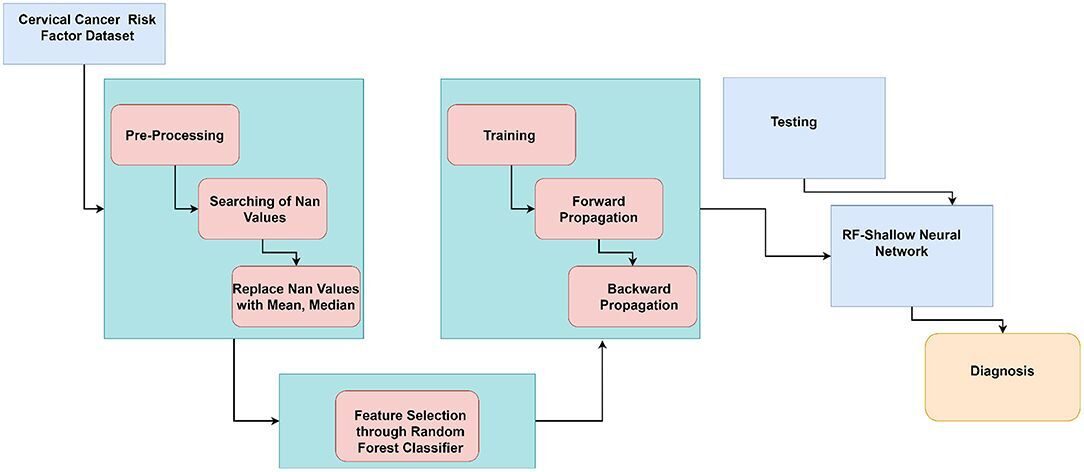
Рисунок 1.
Рисунок 1. иллюстрирует ход нашей работы в виде блок-схемы, состоящей из предварительной обработки и классификации рака шейки матки. Предлагаемый подход состоит из предварительной обработки и классификации рака с использованием алгоритмов машинного обучения и алгоритмов глубокого обучения.Алгоритм 1 показывает работу CervDetect. Случайные выборки были собраны из исходного набора данных о факторах риска рака шейки матки. Для каждой собранной выборки было построено дерево решений, позволяющее сделать прогноз. Подсчет был проведен для каждой итоговой оценки, и функции ранжированы в соответствии с их важностью. Выбранные функции вводятся в неглубокую нейронную сеть, где xi(i=1, 2, … n) — количество входных функций, w21 и w22 — веса, а B1 — константа. y хранит функции, свернутые со случайно инициализированной матрицей фильтров. V хранит результаты применения линейного преобразования к y. O1 сохраняет выходные данные, полученные после применения сигмовидной функции к y, а e вычисляет изменение ошибки относительно весов. Ошибка обратного изменения веса при подаче была рассчитана с помощью цепного правила, и веса обновлены.
4.1. Предварительная обработка данных
В наборе данных о раке шейки матки много пропущенных значений. Отсутствующее значение может означать множество различий. Записи с пропущенными значениями могут быть включены, опущены или среднее значение переменной может быть заменено для отсутствующих числовых характеристик или наиболее частым значением в случае категориальных признаков. Примененная методика устранения количества данных с отсутствующими строками значений уменьшилась с 858 до 737. Мы стремимся масштабировать количество признаков, но не количество входных векторов, используемых в наборе данных. Следующие шаги включены для предварительной обработки данных и превращения их в подходящие входные данные для классификатора.
1. Нэн: Чтобы увидеть отношения между переменными для лечения Нэн. Тем не менее, согласно данным, шкала из более чем 100 значений Nan может повлиять на результаты. Мы заполняем признаки со значением медианы менее 100 значений Nan в них со значениями медианы. 2. Гормональная контрацепция: в диагностической информации данных так много значений Nan. Из-за этого мы не можем рассчитать влияние этой информации и должны их устранить. Вместо этого, используя корреляцию Пирсона, мы решим, какой атрибут влияет на гормональные контрацептивы. Мы заполняем значения Nan коррелированными атрибутами в соответствии с полученной тепловой картой. Если пациентка старше средней выборки или срок беременности меньше средней, пациентка может принимать гормональные контрацептивы. Значения Nan в HC (годы) заполняются средними значениями с использованием атрибутов HC.
3. ВМС: используя корреляцию Пирсона, мы можем решить, какой атрибут является фактором влияния «ВМС». Возраст и количество факторов материнства влияют на функцию ВМС. Это свидетельствует о том, что 80% пациентов, принимающих ВМС, старше среднего возраста. У 70% пациенток, не использующих ВМС, рождается меньше среднего числа беременностей. Мы можем заполнить оставшиеся значения признаков Nan IUD. С помощью правила ВМС (годы) мы можем заполнить значения -1 с помощью правила ВМС. Если пациент принимает ВМС, то UID (годы) будет ненулевым, поэтому нам нужно привести его к средним значениям.
4. ЗППП: кондиломатоз и ЗППП: вульво-промежностный кондиломатоз имеет эффект «ЗППП». Мы никогда не рассматриваем «ЗППП (количество)» и «ЗППП: количество диагнозов», поскольку они являются теми же атрибутами, что и «ЗППП». Основываясь на нашем анализе ЗППП, мы можем удобно заполнить значения Nan равными 1 или нулю, и если у человека есть какое-либо из ЗППП, то ЗППП должно быть 1, другое - 0.
5. Заболевания, передающиеся половым путем. Согласно информации, 73% некурящих больных больны ЗППП. У нас нет значений Nan 75% пациентов, которые не используют ВМС, имеют даже ЗППП. Даже STD (число) являются тем же атрибутом, что и STD. Медианный случай бесполезен, потому что мы используем средние значения для замены. Согласно тепловой карте и нашей осведомленности о предметной области, все ЗППП зависят от функции ЗППП и ЗППП (числа). Мы заполняем значения Nan, используя медиану для конкретных значений, поскольку все ЗППП зависят от определенных ЗППП, и мы не можем быть уверены в заболевании человека.
6. СПИД: Корреляционная функция не дает нам никаких подсказок. Однако мы признаем, что СПИД также является заболеванием, передающимся половым путем. Итак, мы заполняем значения Nan.
7. ЗППП-гепатит В: Этот аспект является результатом фактора ЗППП-ВИЧ. Здесь у нас есть один больной с заболеванием, и это значение ничтожно мало по сравнению с населением. Значение Nan заполняется 0.
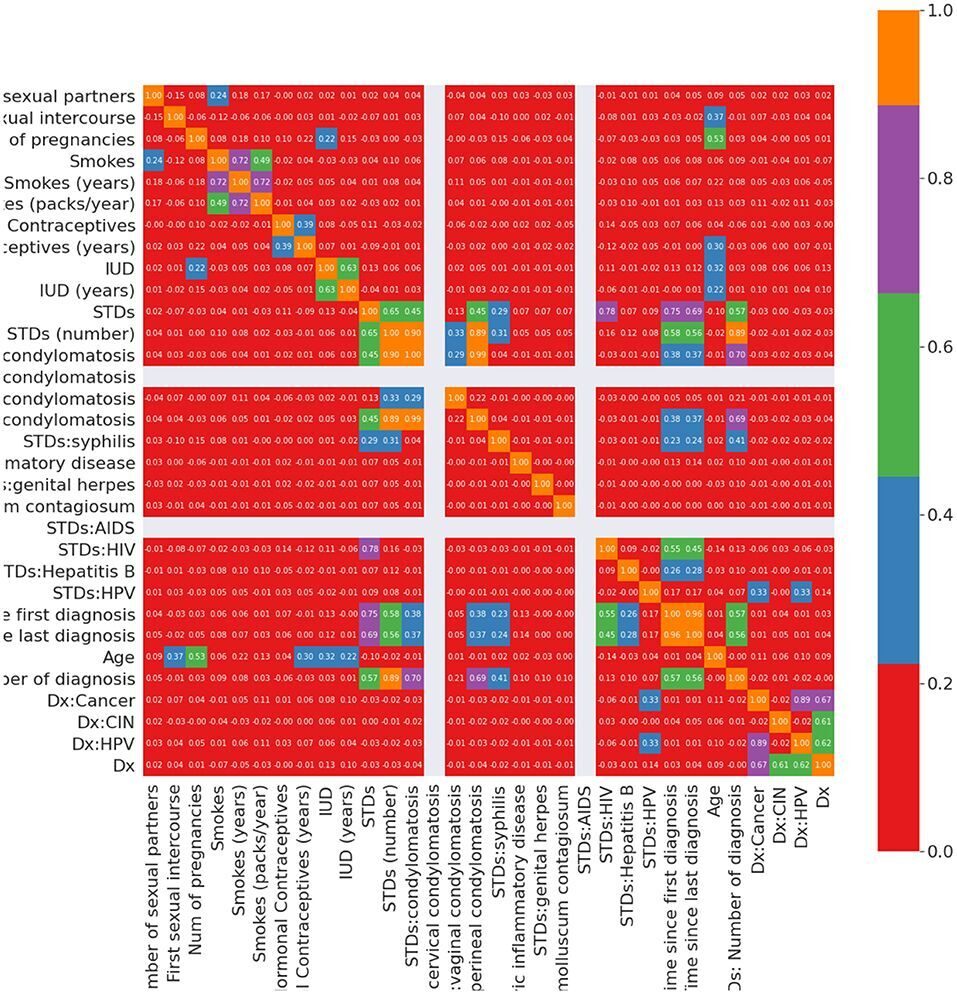
8. ЗППП-ВПЧ: положительных значений ВПЧ недостаточно. Нулевые значения не могут быть определены с помощью значимых атрибутов, и мы заполнили значение Nan 0. 9. ЗППП-время после первого диагноза и ЗППП-время после последнего диагноза: когда ЗППП пациента отрицательные, первый и последний диагнозы не могут быть положительными. Это предположение заполняет значения Nan в этих атрибутах. На рис. 2 показана корреляция Пирсона между атрибутами в наборе данных о факторах риска рака шейки матки после обработки пропущенных значений.
4.2. Случайный лес Модель RF использует последовательность деревьев решений, где каждое дерево в лесу было обучено с использованием начальной выборки элементов данных, поэтому каждый атрибут разделения дерева выбирается из случайного подмножества признаков. Категоризация узоров должна основываться на коллективном голосовании всех деревьев в лесу. Важность атрибута измеряется как уменьшение примеси узла, взвешенное по вероятности приближения к узлу. Вероятность узла может быть определена количеством экземпляров, которые входят в узел, разделенным на общее количество экземпляров. Чем больше значение, тем важнее характеристика. В дереве решений Scikit-learn аппроксимирует значение узлов с использованием значения Джини, учитывая только два дочерних узла (бинарное дерево):
nodeij=WeightjCj−Wl(j)-Cl(j)−Wr(j)-Cr(j) (1)
В уравнении (1) nodeij= важность узла j; Weightj = взвешенные выборки, которые достигают узла j; Cj = примесь j-го узла; l(j)= От левого разделенного дочернего узла на j-м узле; r(j)= От правого разделенного дочернего узла на j-м узле. Важность каждого признака, рассчитанная в дереве решений, определяется уравнением (2):
featureimportanceii=∑j ni(j)/∑knik (2)
Где ∑j= разделение признака I в узле j; ni,j= важность узла j; ∑k= все узлы. В уравнении (3) нормализация этих значений между 0 и 1 выполняется путем взятия суммы всех значений важности объекта и последующего их деления.
normalizedfii=fii(важность признака)∑j fij(все признаки ) (3) normalizedfii=fii(важность признака) ∑j fij(все признаки ) (3) В уравнении (4) на этапе RF последний признак важности равен сумма, включая все деревья. Оценка значимости атрибута для каждого дерева рассчитывается и делится на общую породу дерева. Случайный лес ∑j нормализованный fiijT (4) Случайный лес ∑j нормализованный fiijT (4) Нормализованный fii,j — это нормированная важность признака для I в j-м дереве, а T — общее количество деревьев в лесу. На рис. 3 показан график важности признаков, улучшающий качество обучающего набора данных.

4.3. Искусственные нейронные сети На модели искусственных нейронных сетей влияет структура человеческого мозга, которая соединяет между собой множество биологических нейронов, важных для поддержания когерентной связи. Архитектура ИНС основана на компьютере и состоит из множества простых параллельных процессоров . Это распространенный статистический метод, который может анализировать точные отношения между переменными. В моделях ИНС есть несколько параллельных слоев, и каждый слой состоит из нескольких нейронов. Входной, скрытый и выходной слои — это три разных типа слоев. На входном слое расчеты не проводятся. Вводятся только переменные признаков. Скрытый слой является ключевой частью ИНС и включает в себя различные нейроны, обычно обнаруживаемые путем проверки и ошибки. Требуются линейные и нелинейные функции для нейронов скрытого слоя. На первом этапе нейроны скрытого слоя получают входные переменные, усугубленные соответствующими корреляциями (весами), а за вторым циклом следует нелинейная система индукции, обычно сигмоидальная. Полносвязная ИНС состоит из нейронов. Нейроны разделены на слои, состоящие из одного входного слоя, одного выходного слоя и множества скрытых слоев, при этом вклад каждого слоя в следующем слое является входом в нашем исследовании, и мы концентрируемся на нейронных сетях только с одним слоем скрытых данных. , скрытые нейроны и один выход. 4.4. Архитектура мелкой нейронной сети Были построены различные типы нейронных сетей, как поверхностные, так и глубокие. Термины «мелкий» и «глубокий» относятся к нейронной сети с минимальным количеством слоев, о которых обычно известно, что они имеют общий скрытый слой. Глубокие нейронные сети используются нейронными сетями, которые содержат несколько глубоких слоев. Эти типы сетей выполняют различные задачи, и фундаментальная структура неглубоких сетей позволяет им это делать. Почти все неглубокие сети имели входной слой, один скрытый слой и выходной слой. Количество скрытых узлов в слое — единственный другой гиперпараметр. Сети используют онлайн-обучение вместо пакетного обучения, которое использует простое обратное распространение и градиентный спуск. Кроме того, в неглубоких сетях использовался алгоритм обратного распространения масштабированного сопряженного градиентного спуска (SCG). На рис. 4 показана фундаментальная модель неглубоких нейронных сетей.

Нейроны являются атомарным компонентом нейронной сети. Для входных данных определяются выходные данные, а выходные данные передаются на следующий слой в качестве входного вектора. Нейрон можно представить как слияние различных сегментов: 1. Первая секция вычисляет выход Y, используя входные параметры и веса. 2. Второй раздел выполняет активацию на Y, чтобы дать окончательную производительность нейрона A. Скрытый слой состоит из нескольких нейронов, каждый из которых выполняет указанные ниже 5 и 6 уравнения. Те два нейрона, которые находятся в скрытом слое внешней нейронной сети, оцениваются следующим образом:
Y[1]1=w[1]1Tz + b[1]1,a[1]1= σ(y[1]1) ( 5)
Y[1]2=w[1]2Tz +b[1]2,a [1]2= σ(y[1]2) (6)
Где число в верхнем индексе [i] — номер слоя, а номер подписки j — количество нейронов в конкретном слое. Y — входной вектор, состоящий из трех компонентов. Wi представляет веса, связанные с каждой входной переменной, а bi представляет коэффициент смещения, связанный с каждой линией, скрытой линией и выходным слоем. Z[i]j — это просто промежуточный результат, связанный с j нейронами, обнаруженными в i-м слое. A[i]j — это конечный результат, связанный с нейроном j в i-м слое. Сигма — это функция активации, которая сжимает входное значение в диапазоне (0,1). Математически это описывается уравнением (7):
σ=1 /1 + e−yi (7)
Уравнение (8) представляет все Z промежуточных выходов в одной матрице умножения.
Z1=X[1]TX +b1 (8)
A[1]1= σ(Z1) (9)
(9) Приведенное выше уравнение (9) представляет всю активацию A в одной матрице умножения. Чтобы вычислить результат для входного вектора y, выполняются следующие шаги, как указано в уравнениях (10), (11), (12) и (13) ниже. Эти шаги также можно назвать распространением с прямой связью.
Z1=W[1]TY b1 (10)
A[1]1= σ(Z1) (11)
Z2=W [2]TA1 +b2 (12)
Zfinal=A[2]= σ(Z2) (13)
Где уравнение (10) измеряет Z (18) промежуточный выход первого скрытого слоя. Уравнение (11) используется для измерения конечной продукции А (18) первого скрытого слоя. Уравнение (12) вычисляет промежуточное значение Z слоя обработки Z. Уравнение (13) вычисляет конечный продукт A выходного слоя, который теперь является результатом всей нейронной сети. Когда результаты получены из скрытого слоя каждого нейрона, они передаются на следующий слой, где каждый нейрон в выходном слое завершает значения.
Y[2]1=w[2]1out(y1) w[2]2out(y2)+ ..+ w[2]14out(y14) + b[2]2 (14)
a1[2]= σ(Y1[2]) (15)
Y[2]15=w[2]30out(y1)+ w[2]31out(y2)+ ..+ w[2]43out(y15) + b[2]2 (16)
a[2]50= σ(Y[2] 50) (17)
Уравнения (14–17) используются для определения ошибки после получения результатов для каждого нейрона в выходном слое. Когда это критическая ошибка, она будет избегать обратного распространения, чтобы изменить предыдущие веса, чтобы получить минимальную ошибку в процессе прямой связи. 5. Результаты и обсуждение В нашей работе наиболее значимая мера точности диагностики рака шейки матки используется для расчета производительности RF-мелкой нейронной сети. Истинный положительный результат (TP) идентичен отвергнутым и представляет собой количество больных раком, отмеченных как биопсия. Ложноположительный результат (FP) противоположен неправильному отрицанию и представляет нормальных пациентов как больных раком. Истинный отрицательный результат (TN) равен количеству правильно идентифицированных пациентов, представляющих собой количество здоровых пациентов, идентифицированных как нормальные. Ложноотрицательный (FN) равен любому неправильно идентифицированному, что представляет собой количество больных раком, идентифицированных как нормальные пациенты. В таблице 2 показана матрица путаницы.

Таблица 2
Точность: пропорция количества записей о пациентах, правильно классифицированных по отношению к общему количеству записей о пациентах в наборе данных, как показано в уравнении (18).
AC=TP+TN/Tp+TN+FP+FN (18)
Истинный положительный коэффициент (TPR): он идентичен коэффициенту обнаружения (DR). TPR указывает пропорцию количества правильно определенных записей о пациентах по отношению к общему количеству записей о пациентах, как показано в уравнении (19).
TPR=TP/TP+FN (19)
Коэффициент ложноположительных результатов (FOR): отношение количества ошибочно отклоненных записей к общему количеству записей, как показано в уравнении (20).
FPR=FP/FP+TN (20)
В этом исследовании мы предложили новый метод под названием RF-мелкая нейронная сеть для диагностики рака шейки матки, так как влияние неправильного диагноза при раке шейки матки или наоборот велико. Интеллектуальный анализ данных предоставляет инструменты и методы для извлечения важных данных из огромного набора данных путем анализа. На протяжении всего этого исследования модели машинного обучения (РЧ и поверхностная нейронная сеть) использовались для диагностики рака шейки матки, чтобы продемонстрировать важность построения модели с очисткой данных, заменой нулевых значений и реализацией процедуры выбора признаков для достижения большей точности. предсказание оптимального функционального подмножества. В этой методологии использовались методологии машинного обучения для данных о раке шейки матки для оценки эффективности моделей классификатора с учетом всех медицинских записей. Отсутствующие записи набора данных заполняются путем замены отсутствующих значений в строках их средним значением и медианой путем нахождения корреляции Пирсона между переменными. Реализация RF в качестве метода выбора признаков и обучение неглубокой нейронной сети с помощью оптимального подмножества признаков были выбраны на основе значения переменных. В дополнение к одному целевому атрибуту биопсии для диагностики рака шейки матки следующие атрибуты в таблице 3 были определены как более важные характеристики среди набора данных о факторах риска рака шейки матки.